Deep Residual Learning for Image Recognition
Paper - arXiv
Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun (Microsoft Research)
Hypothesis / Main methods:
When deeper networks are able to start converging, the degradation problem occurs: the accuracy gets saturated and degrades rapidly. It is easier to optimize / fine tune the residual effect of each layer on the previous layer. Thus in their architecture, each layer learns the residual to the input.
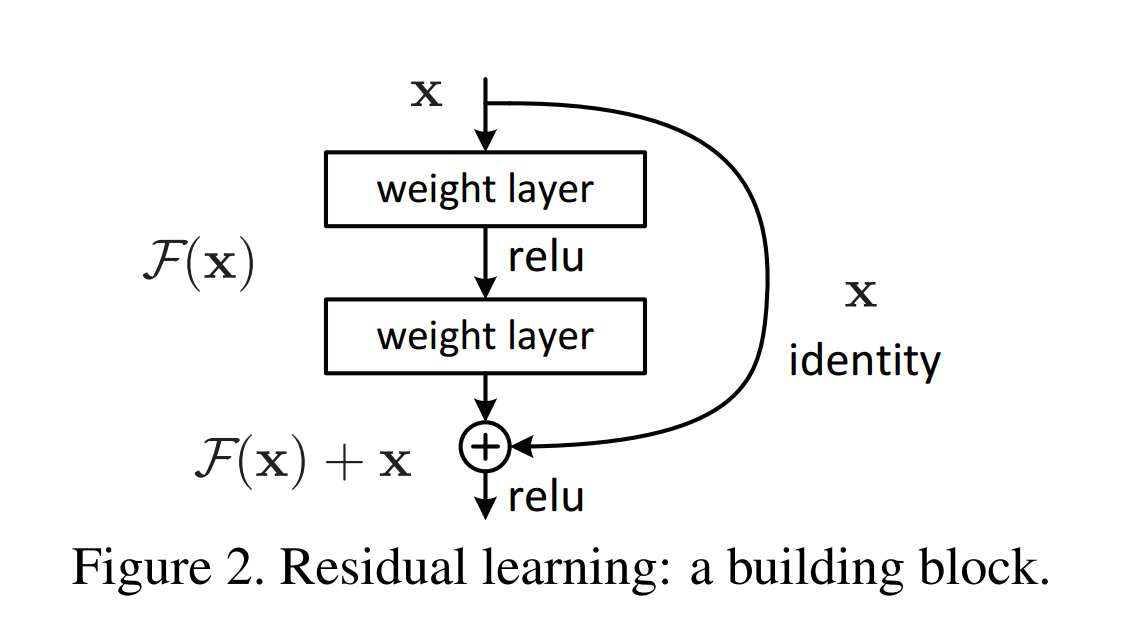
The output is element-wise addition of input x to F(x). F(x) is the residual.